7 Methods to Boost the Accuracy of AI Model
Share

What is AI model?
In AI/ML, a model replicates a decision process to enable automation and understanding. AI/ML models are mathematical algorithms that are “trained” using data and human expert input to replicate a decision an expert would make when provided that same information.
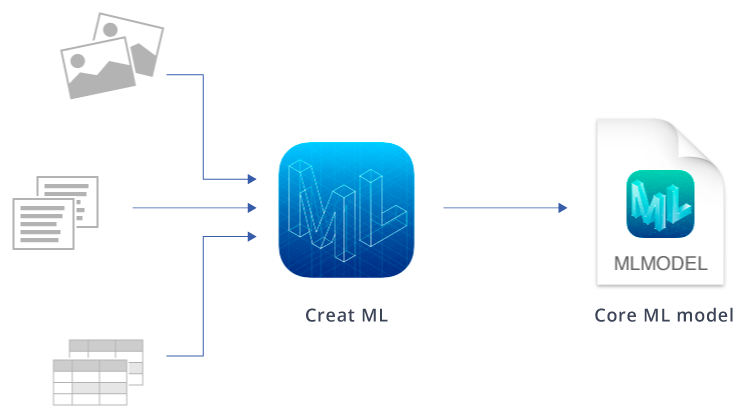
Machine learning tool called Create ML
Ideally, the model should also reveal the rationale behind its decision to help interpret the decision process (though frequently challenging).
Most often, the training processes a large amount of data through an algorithm to maximize likelihood or minimize cost, yielding a trained model. Analyzing data from many wells in different conditions, the model learns to detect all the types of patterns and distinguish these from normal operation. A model attempts to replicate a specific decision process that a team of experts would review all available data.
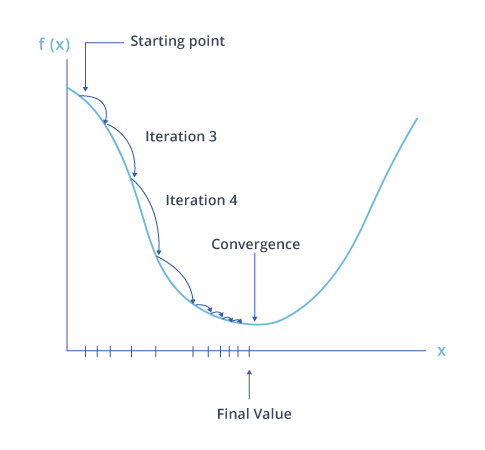
Cost function graph to evaluate loss of the ML model
The challenge to building AI/ML models has been to detect and diagnose these complex and dynamic conditions as they unfold at the well without burdening personnel with tedious monitoring. Ask any operator or engineer to describe what friction, tubing leaks, worn pumps, and most other common problems look like, and they can describe typical traits. But in the same breath, these experts will tell you that every well is unique, and the signal pattern associated with each type of event depends on many different conditions unique to that well, pump, and reservoir. Anyone who has tried to configure individual pump controllers to handle “it depends,” given so many potential situations, knows it is nearly impossible.
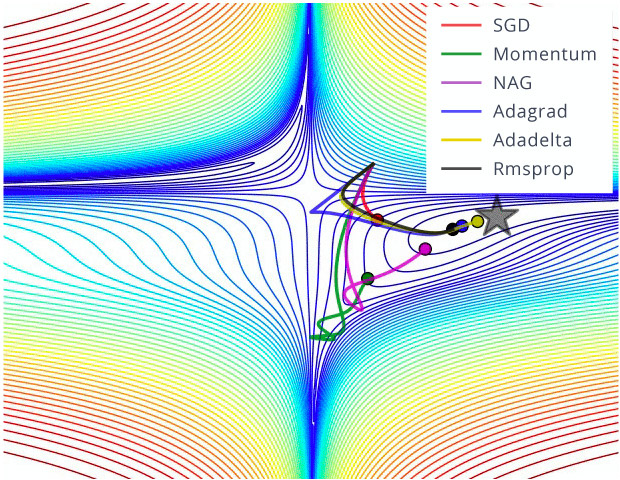
Optimizer functions are used to minimize the cost of the ML model
What does Machine Learning Model Accuracy Mean?
Machine learning model accuracy is the measurement used to determine which model best identifies relationships and patterns between variables in a dataset based on the input or training data. The better a model can generalize to ‘unseen’ data, the better predictions and insights it can produce, which deliver more business value.
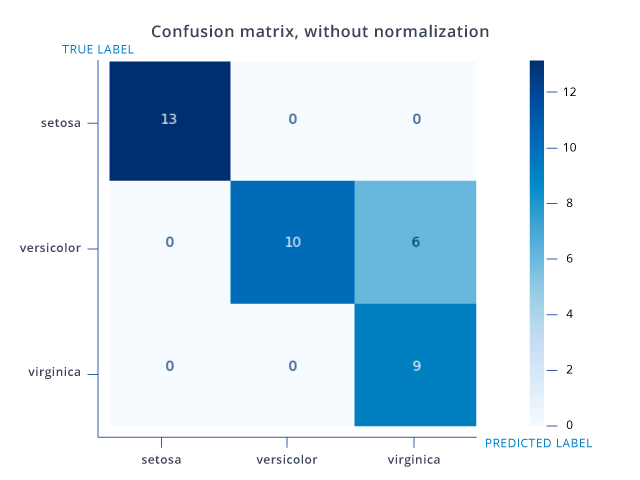
Confusion matrix is used to evaluate the accuracy of AI model
Why is Model Accuracy Important?
Companies use machine learning models to make practical business decisions, and more accurate model outcomes result in better decisions. The cost of errors can be huge, but optimizing model accuracy mitigates that cost. Of course, there is a point of diminishing returns when the value of developing a more accurate model will not result in a corresponding profit increase. Still, often it is beneficial across the board. A false positive cancer diagnosis, for example, costs both the hospital and the patient. The benefits of improving model accuracy help avoid the considerable time, money, and undue stress.
8 Methods to Boost the Accuracy of a Model
1. Add more data
Having more data is always a good idea. It allows the “data to tell for itself,” instead of relying on assumptions and weak correlations. The presence of more data results in better and accurate models.
2. Treat missing and Outlier values
The unwanted presence of missing and outlier values in the training data often reduces a model's accuracy or leads to a biased model. It leads to inaccurate predictions because we do not analyze the behavior and relationship with other variables correctly. Therefore, it is essential to treat missing and outlier values well.
3. Feature Engineering
Feature engineering is highly influenced by Hypotheses generation. Good hypothesis results in good features. Feature engineering process can be divided into two steps:
- Feature transformation: There are various scenarios where feature transformation is required:
- Changing a variable from the original scale to a scale between zero and one is known as data normalization. For example: If a data set has 1st variable in meter, 2nd in centimeter, and 3rd in kilo-meter, in such case, before applying any algorithm, we must normalize these variables in the same scale.
- Some algorithms work well with normally distributed data. Therefore, we must remove the skewness of variable(s). There are methods like logarithmic, square root, or inverse of the values to remove skewness.
- Some times, creating bins of numeric data works well since it handles the outlier values. Numeric data can be made discrete by grouping values into bins. This process is known as data discretization.
- Feature Creation: Deriving new variable(s ) from existing variables is known as 'feature creation.' It helps to unleash the hidden relationship of a data set. Let’s say we want to predict the number of transactions in a store based on transaction dates. Transaction dates may not have a direct correlation with a number of transactions, but if we look at the day of a week, it may have a higher correlation. In this case, the information about the day of a week is hidden. We need to extract it to make the model better.
4. Feature Selection
Feature Selection is a process of finding out the best subset of attributes that better explains the independent variables' relationship with the target variable.
- Domain Knowledge: Based on domain experience, we select feature(s), which may significantly impact the target variable.
- Visualization: As the name suggests, it helps to visualize the relationship between variables, making your variable selection process easier.
- Statistical Parameters: We also consider the p-values, information values, and other statistical metrics to select the right features.
- Principal Component Analysis (PCA): It helps represent training data into lower-dimensional spaces but still characterizes the data's inherent relationships. It is a type of dimensionality reduction technique. There are various methods to reduce the dimensions (features) of training data like factor analysis, low variance, higher correlation, backward/ forward feature selection, etc.
5. Multiple algorithms
Hitting at the right machine learning algorithm is the ideal approach to achieve higher accuracy. But, it is easier said than done.
This intuition comes with experience and incessant practice. Some algorithms are better suited to a particular type of data sets than others. Hence, we should apply all relevant models and check the performance.
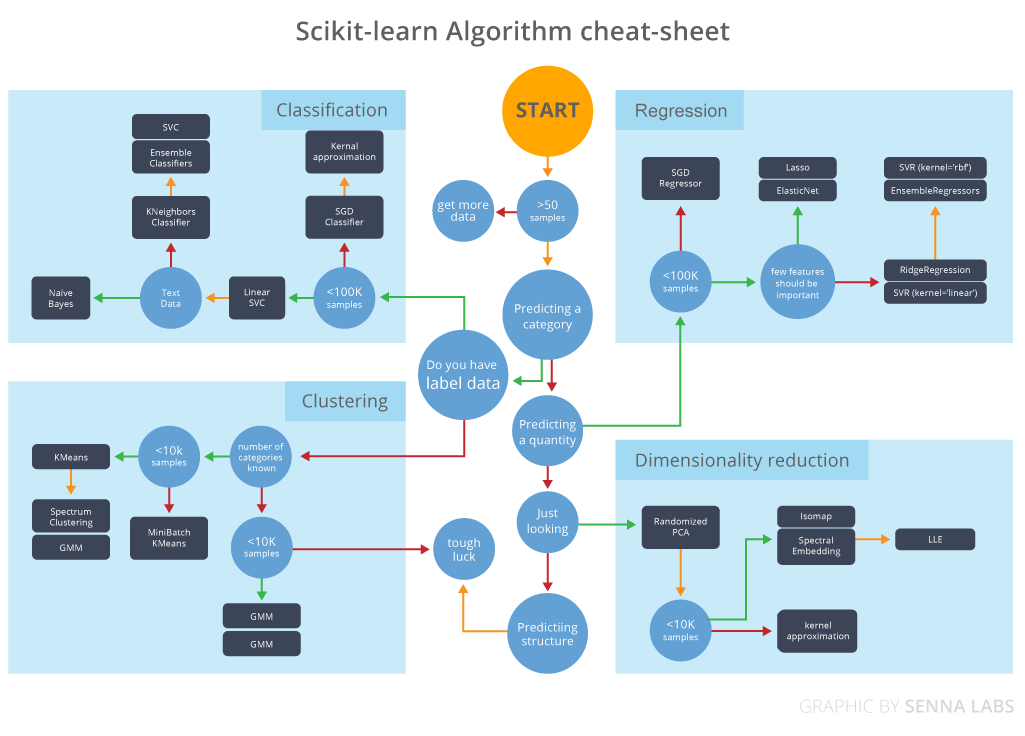
6. Algorithm Tuning
The objective of parameter tuning is to find the optimum value for each parameter to improve the accuracy of the model. To tune these parameters, you must have a good understanding of these meanings and their individual impact on the model. You can repeat this process with some well-performing models.
RandomForestClassifier(n_estimators=10, criterion='gini', max_depth=None,min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features='auto', max_leaf_nodes=None,bootstrap=True, oob_score=False, n_jobs=1, random_state=None, verbose=0, warm_start=False,class_weight=None)Scikit learns Random forest algorithm parameter tuning
7. Cross-Validation
Cross-Validation is one of the most critical concepts in data modeling. Try to leave a sample on which you do not train the model and test the model on this sample before finalizing the model.
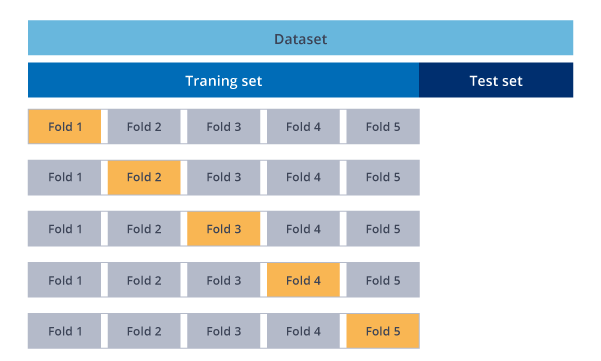
K-Fold Cross Validation

Share

Keep me postedto follow product news, latest in technology, solutions, and updates
Related articles
Explore all


