
Choosing the appropriate machine algorithm in real use cases

In the real machine learning project, a typical question that always asked is; when facing a wide variety of machine algorithm, is "Which algorithm should we use ?" but the answer also varies from many factors, such as; the size, quality, characteristic of data, the available computing resources, the urgency of tasks, and so on. With this variety situation of using an appropriate algorithm, even an experienced data scientist might not able to tell exactly which algorithm will perform the best before trying different algorithms. In fact, we are not advocating a one and done approach, but we do hope to provide some guidance on which algorithms to try first depending on some clear factors.
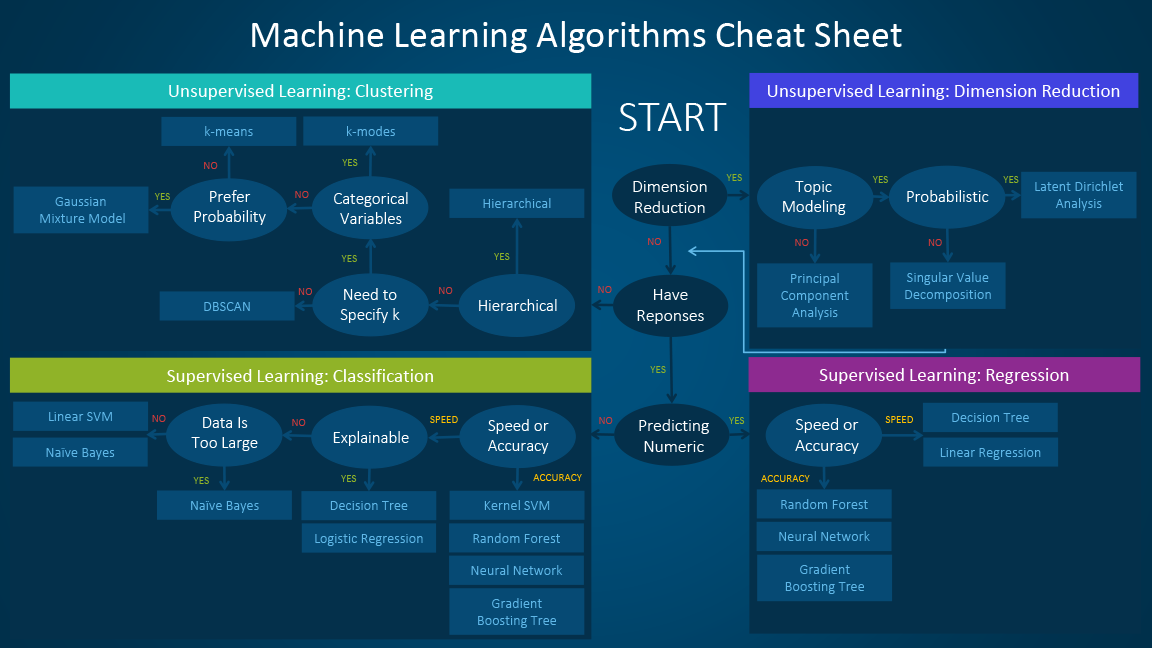
Photo source: blogs.sas.com
The machine learning algorithm cheat sheet above helps you to choose from a variety of machine learning algorithms to find the appropriate algorithm for your specific problems. This article walks you through the process of how to use the sheet. Since the cheat sheet is designed for beginner data scientists and analysts, we will make some simplified assumptions when talking about the algorithms.
When choosing an algorithm
When choosing an algorithm, always take these aspects into account: accuracy, training time and ease of use. Many users put the accuracy first, while beginners tend to focus on algorithms they know best.
When presented with a dataset, the first thing to consider is how to obtain results, no matter what those results might look like. Beginners tend to choose algorithms that are easy to implement and can obtain results quickly. This works fine, as long as it is just the first step in the process. Once you obtain some results and become familiar with the data, you may spend more time using more sophisticated algorithms to strengthen your understanding of the data, hence further improving the results.
Please note that the best algorithms might not be the methods that have achieved the highest reported accuracy, as an algorithm usually requires careful tuning and extensive training to obtain its best achievable performance.
When to use specific algorithms
Next step, let's looking more closely at individual algorithms that can help you understand what they provide and how they are used. These descriptions provide more details and give additional tips for when to use specific algorithms
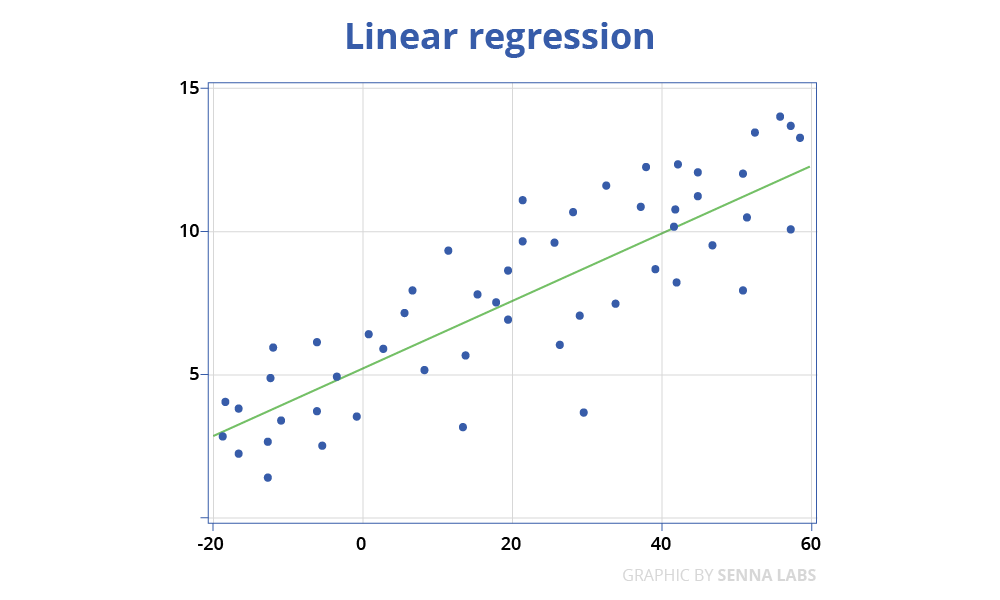
Linear regression
linear regression was developed in the field of statistics and is studied as a model for understanding the relationship between input and output numerical variables, but has been borrowed by machine learning. It is both a statistical algorithm and a machine learning algorithm.
For example, in a simple regression problem (a single x and a single y), the form of the model would be:
y = B0 + B1*x
Where B0 is the bias coefficient and B1 is the coefficient for the height column. We use a learning technique to find a good set of coefficient values. Once found, we can plug in different height values to predict the weight.
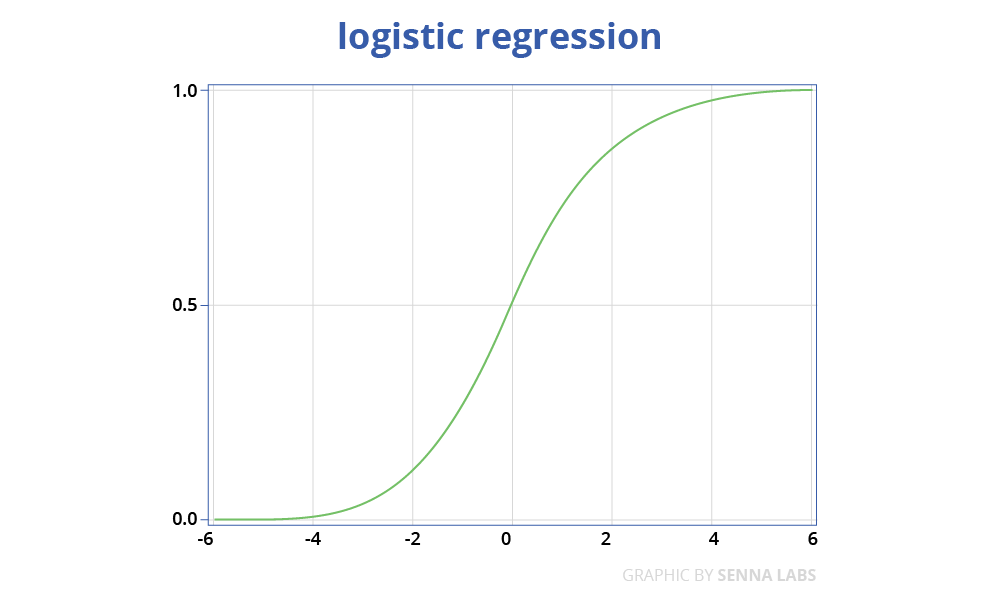
Logistic regression
Logistic regression is a simple, fast yet powerful classification algorithm. Here we discuss the binary case where the dependent variable only takes binary values (it which can be easily extended to multi-class classification problems).
y = 1 / 1 - e^(-x)
In logistic regression, we use a different hypothesis class to try to predict the probability that a given example belongs to the "1" class versus the probability that it belongs to the "-1" class. Specifically, we will try to learn a function of the form: and. Here is a sigmoid function. Given the training examples, the parameter vector can be learned by maximizing the log-likelihood of given the data set.
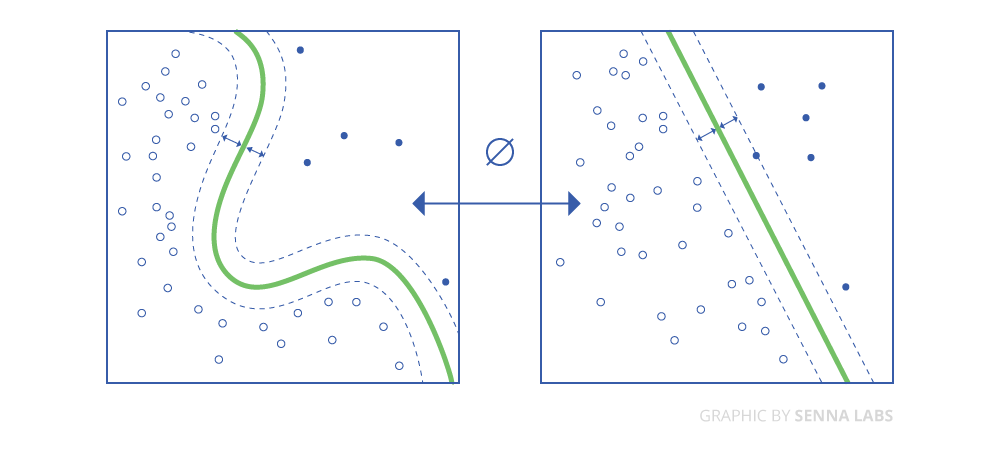
Linear SVM and kernel SVM
Kernel tricks are used to map non-linearly separable functions into a higher dimension linearly separable function. A support vector machine (SVM) training algorithm finds the classifier represented by the normal vector and bias of the hyperplane.
A support vector machine (SVM) training algorithm finds the classifier represented by the normal vector and bias of the hyperplane. This hyperplane (boundary) separates different classes by as wide a margin as possible. The problem can be converted into a constrained optimization problem.
Trees, forest
Decision trees, random forest, and gradient boosting are all algorithms based on decision trees. There are many variants of decision trees, but they all do the same thing which is subdivide the feature space into regions with mostly the same label. Decision trees are easy to understand and implement. However, they tend to overfit data when we exhaust the branches and go very deep with the trees. Random Forrest and gradient boosting are two popular ways to use tree algorithms to achieve good accuracy as well as overcoming the over-fitting problem.
(Overfitting is a modeling error that occurs when a function is too closely fit a limited set of data points)
K-nearest neighbor
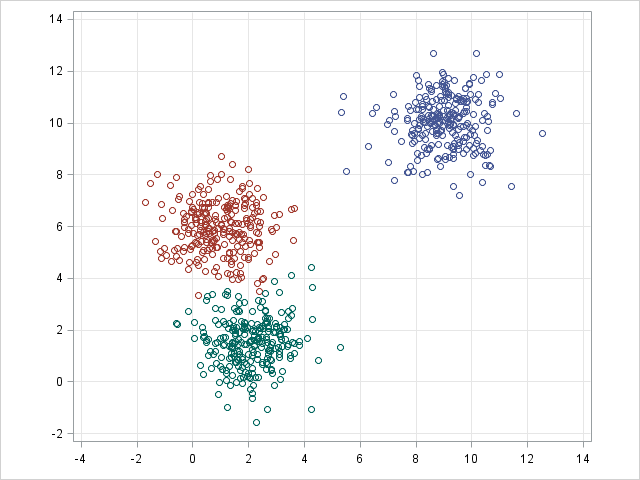
K-nearest neighbor is an unsupervised machine learning algorithm that aims to partition n observations into k clusters. K-means define hard assignment: the samples are to be and only to be associated with one cluster. GMM, however, defines a soft assignment for each sample. Each sample has a probability to be associated with each cluster. Both algorithms are simple and fast enough for clustering when the number of clusters k is given.
PCA
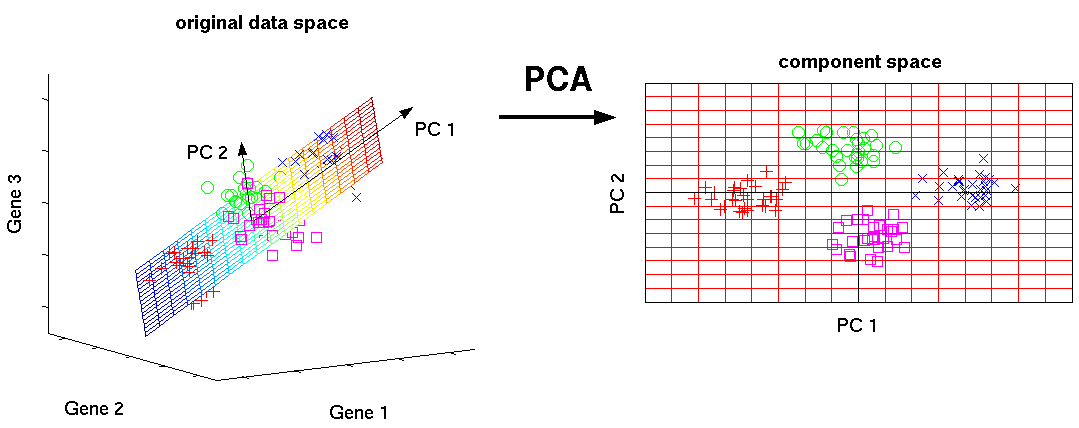
Principal component analysis (PCA) is a technique used to emphasize variation and bring out strong patterns in a dataset. It's often used to make data easy to explore and visualize.
With three dimensions, PCA is more useful, because it's hard to see through a cloud of data. In the example below, the original data are plotted in 3D, but you can project the data into 2D through a transformation no different than finding a camera angle: rotate the axes to find the best angle.
Neural networks and deep learning
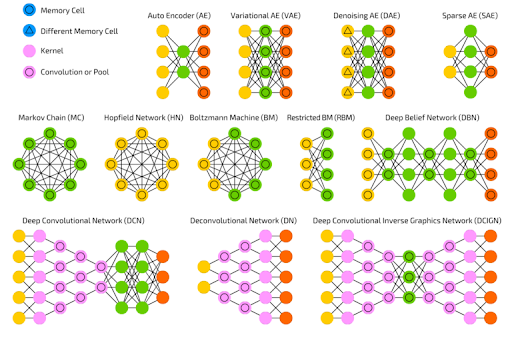
A variety of neural network
In recent years, the improvement of training techniques such as unsupervised pre-training and layer-wise greedy training has led to a resurgence of interest in neural networks. Increasingly powerful computational capabilities, such as graphical processing unit (GPU), Google's tensor processing unit(TPU), massively parallel processing (MPP), have also spurred the revived adoption of neural networks. The resurgent research in neural networks has given rise to the invention of models with thousands of layers.
Deep neural networks have been very successful in supervised learning. When used for speech and image recognition, deep learning performs as well as, or even better than, humans. Applied to unsupervised learning tasks, such as feature extraction, deep learning also extracts features from raw images or speech with much less human intervention.
Reference


Subscribe to follow product news, latest in technology, solutions, and updates
Other articles for you


Let’s build digital products that are simply awesome !
We will get back to you within 24 hours!Go to contact us






